
ConcurrentHashMap扩容实现机制
jdk8中,采用多线程扩容。整个扩容过程,通过CAS设置sizeCtl,transferIndex等变量协调多个线程进行并发扩容。
扩容相关的属性
nextTable
扩容期间,将table数组中的元素 迁移到 nextTable。
|
|
sizeCtl属性
|
|
多线程之间,以volatile的方式读取sizeCtl属性,来判断ConcurrentHashMap当前所处的状态。通过cas设置sizeCtl属性,告知其他线程ConcurrentHashMap的状态变更。
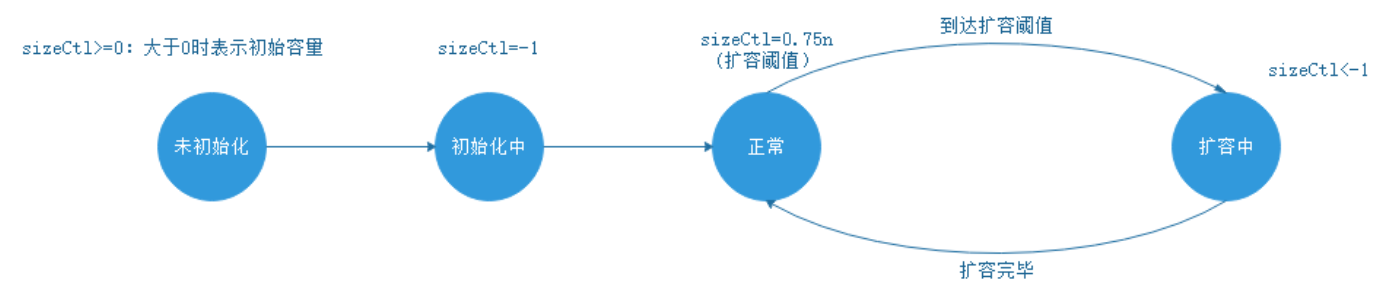
不同状态,sizeCtl所代表的含义也有所不同。
- 未初始化:
- sizeCtl=0:表示没有指定初始容量。
- sizeCtl>0:表示初始容量。
- 初始化中:
- sizeCtl=-1,标记作用,告知其他线程,正在初始化
- 正常状态:
- sizeCtl=0.75n ,扩容阈值
- 扩容中:
- sizeCtl < 0 : 表示有其他线程正在执行扩容
- sizeCtl = (resizeStamp(n) << RESIZE_STAMP_SHIFT) + 2 :表示此时只有一个线程在执行扩容
ConcurrentHashMap的状态图如下:
transferIndex属性
|
|
扩容索引,表示已经分配给扩容线程的table数组索引位置。主要用来协调多个线程,并发安全地获取迁移任务(hash桶)。
1 在扩容之前,transferIndex 在数组的最右边 。此时有一个线程发现已经到达扩容阈值,准备开始扩容。
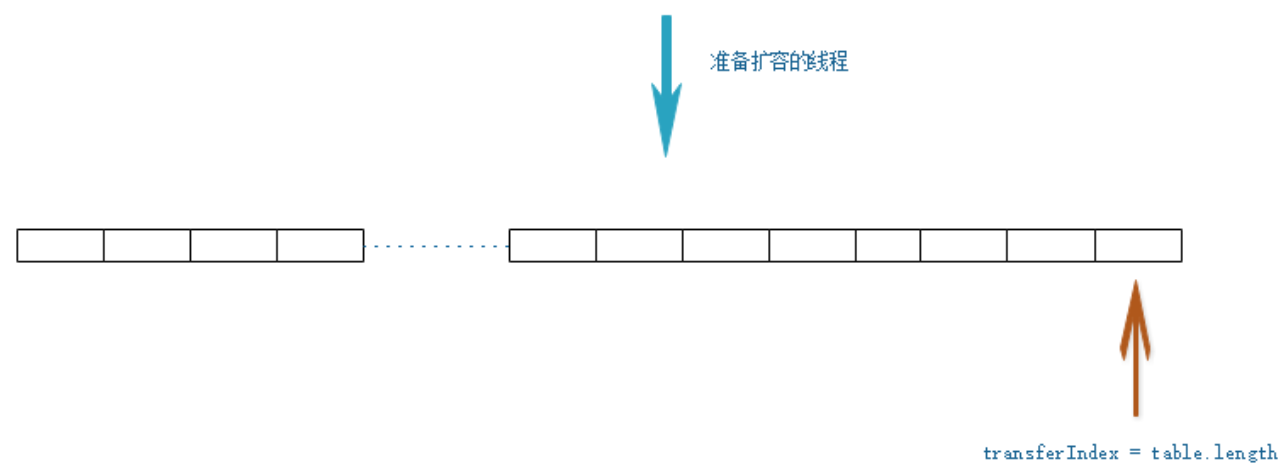
2 扩容线程,在迁移数据之前,首先要将transferIndex右移(以cas的方式修改 transferIndex=transferIndex-stride(要迁移hash桶的个数)),获取迁移任务。每个扩容线程都会通过for循环+CAS的方式设置transferIndex,因此可以确保多线程扩容的并发安全。
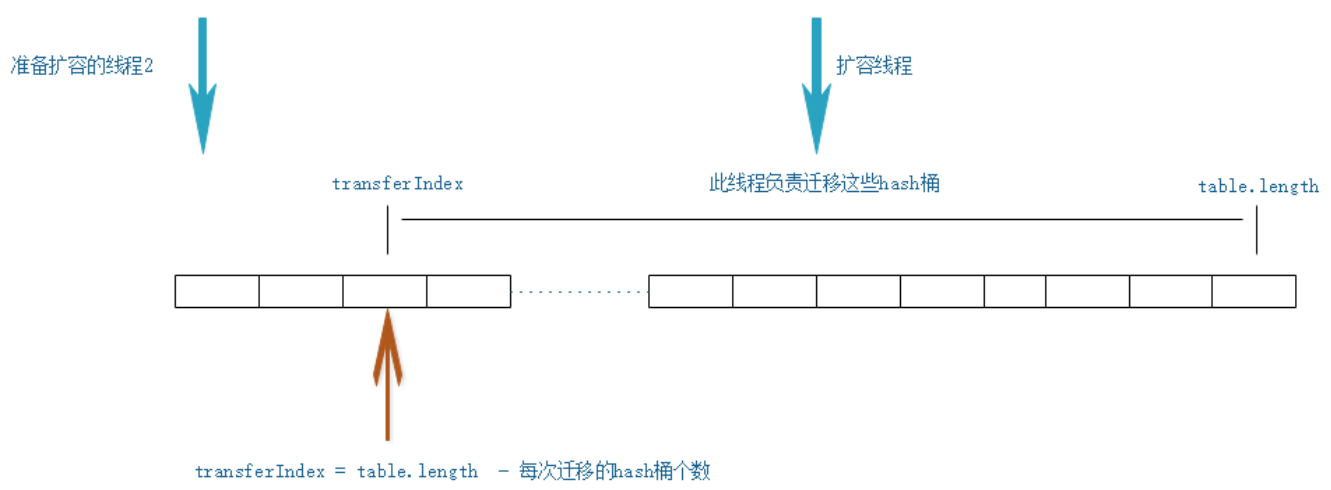
换个角度,我们可以将待迁移的table数组,看成一个任务队列,transferIndex看成任务队列的头指针。而扩容线程,就是这个队列的消费者。扩容线程通过CAS设置transferIndex索引的过程,就是消费者从任务队列中获取任务的过程。为了性能考虑,我们当然不会每次只获取一个任务(hash桶),因此ConcurrentHashMap规定,每次至少要获取16个迁移任务(迁移16个hash桶,MIN_TRANSFER_STRIDE = 16)
cas设置transferIndex的源码如下:
|
|
ForwardingNode节点
- 标记作用,表示其他线程正在扩容,并且此节点已经扩容完毕
- 关联了nextTable,扩容期间可以通过find方法,访问已经迁移到了nextTable中的数据
|
|
何时扩容
1 当前容量超过阈值
|
|
|
|
2 当链表中元素个数超过默认设定(8个),当数组的大小还未超过64的时候,此时进行数组的扩容,如果超过则将链表转化成红黑树
|
|
|
|
3 当发现其他线程扩容时,帮其扩容
|
|
扩容过程分析
- 线程执行put操作,发现容量已经达到扩容阈值,需要进行扩容操作,此时transferindex=tab.length=32
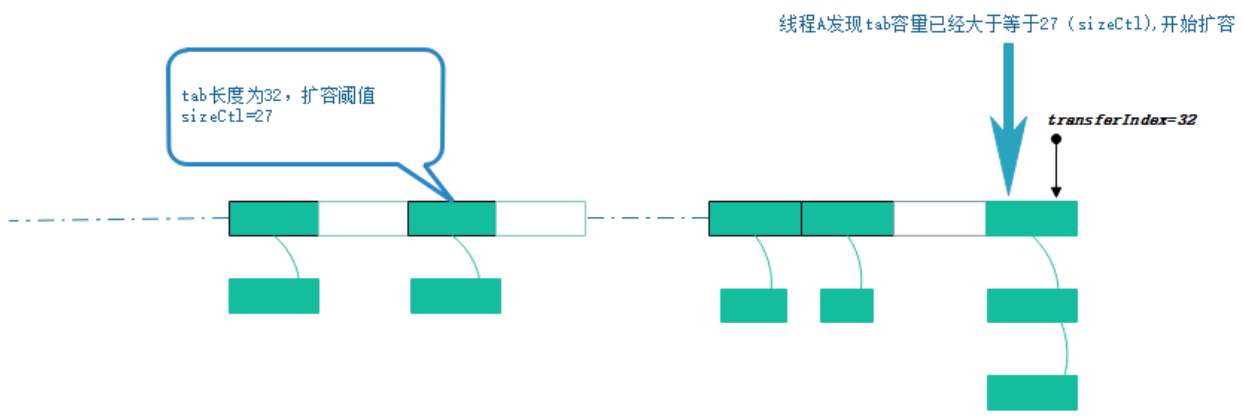
- 扩容线程A 以cas的方式修改transferindex=32-16=16 ,然后按照降序迁移table[32]–table[16]这个区间的hash桶
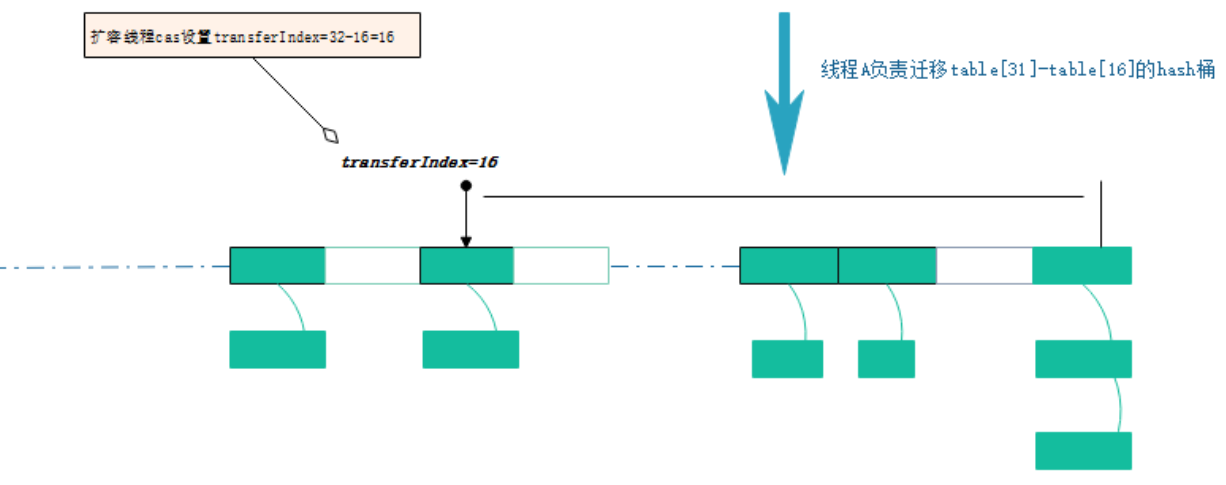
- 迁移hash桶时,会将桶内的链表或者红黑树,按照一定算法,拆分成2份,将其插入nextTable[i]和nextTable[i+n](n是table数组的长度)。 迁移完毕的hash桶,会被设置成ForwardingNode节点,以此告知访问此桶的其他线程,此节点已经迁移完毕。
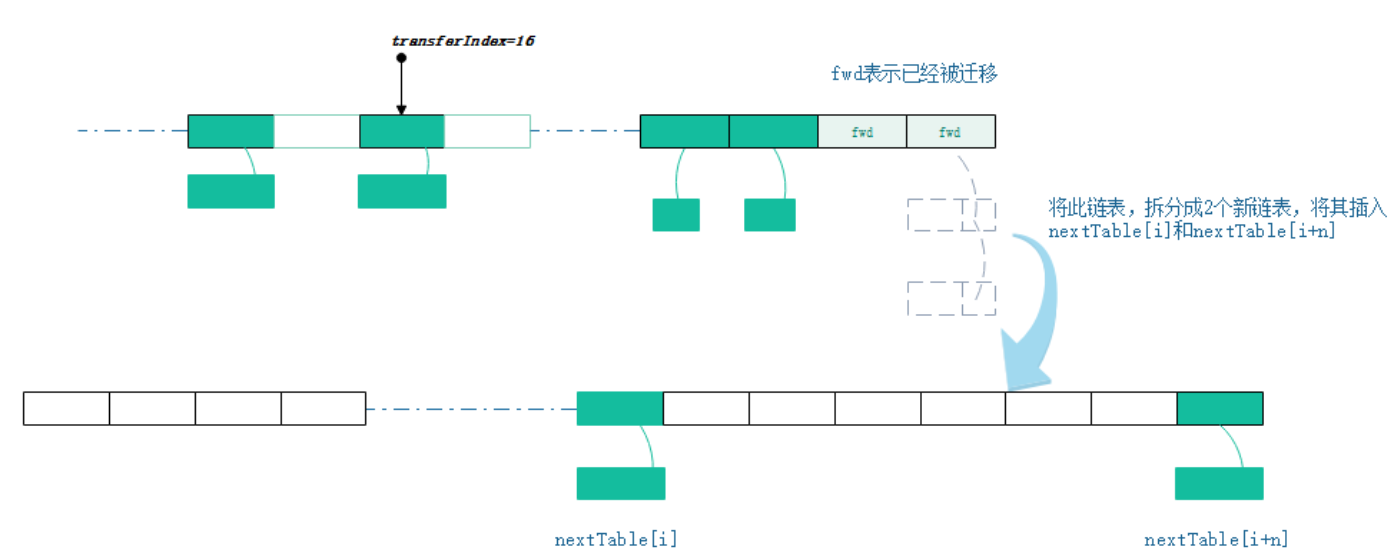
相关代码如下:
|
|
- 此时线程2访问到了ForwardingNode节点,如果线程2执行的put或remove等写操作,那么就会先帮其扩容。如果线程2执行的是get等读方法,则会调用ForwardingNode的find方法,去nextTable里面查找相关元素。
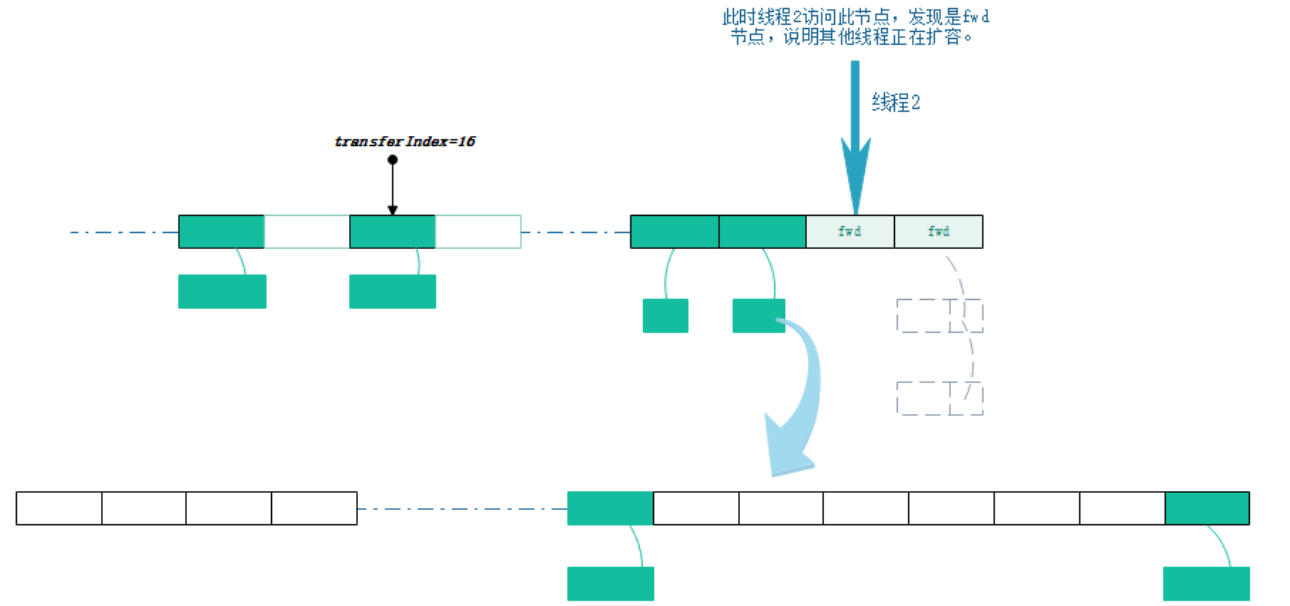
- 线程2加入扩容操作

- 如果准备加入扩容的线程,发现以下情况,放弃扩容,直接返回。
- 发现transferIndex=0,即所有node均已分配
- 发现扩容线程已经达到最大扩容线程数

部分源码分析
tryPresize方法
协调多个线程如何调用transfer方法进行hash桶的迁移(addCount,helpTransfer 方法中也有类似的逻辑)
|
|
transfer方法
负责迁移node节点
|
|
总结
多线程无锁扩容的关键就是通过CAS设置sizeCtl与transferIndex变量,协调多个线程对table数组中的node进行迁移。
勘误:tab.length为32,扩容阈值是32*0.75=24

