
JDK1.8 HashMap源码分析
HahsMap实现了Map接口。其继承关系如下图:
HashMap有两个影响性能的重要参数:初始容量和加载因子。容量是Hash表中桶的个数,当HashMap初始化时,容量就是初始容量。加载因子是衡量hash表多满的一个指标,用来判断是否需要增加容量。当HashMap需要增加容量时,将会导致rehash操作。
默认情况下,0.75的加载因子在时间和空间方面提供了很好的平衡。加载因子越大,增加了空间利用率但是也增加了查询的时间。
构造器
底层结构
JDK1.8之前的结构
在JDK1.7之前,HashMap采用的是数组+链表的结构,其结构图如下:
左边部分代表Hash表,数组的每一个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。

JDK1.8的结构
JDK1.8 之前的 HashMap 都采用上图的结构,都是基于一个数组和多个单链表,hash 值冲突的时候,就将对应节点以链表形式存储。如果在一个链表中查找一个节点时,将会花费 O(n) 的查找时间,会有很大的性能损失。到了JDK1.8,当同一个Hash值的节点数不小于8时,不再采用单链表形式存储,而是采用红黑树,如下图所示:

Node介绍
Node是map的接口中的内部接口Map.Entry的实现类,用于存储HashMap中键值对的对象,是HashMap中非常重要的一个内部类,随便提一下,HashMap中有非常多的内部类,本文没做过多的介绍,读者可以自己翻看一下源码,因为篇幅实在太长了…在这里就简单的讲一下,大部分的内部类都是用于集合操作的,如keySet,values,entrySet等方法.
内部组成
|
|
重要的字段
HashMap中有几个重要的字段,如下:
|
|
红黑树的关键参数
|
|
构造方法
HashMap一共有4个构造方法,主要的工作就是完成容量和加载因子的赋值。Hash表都是采用的懒加载方式,当第一次插入数据时才会创建。
|
|
基本操作
确定哈希桶数组索引位置
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。前面说过 HashMap 的数据结构是数组和链表的结合,所以我们当然希望这个 HashMap 里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用 hash 算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表,大大优化了查询的效率。HashMap 定位数组索引位置,直接决定了 hash 方法的离散性能。先看看源码的实现(方法一+方法二):
|
|
这里的 Hash 算法本质上就是三步:取 key 的 hashCode 值、高位运算、取模运算。
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用方法一所计算得到的 Hash 码值总是相同的。我们首先想到的就是把 hash 值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,在 HashMap 中是这样做的:调用方法二来计算该对象应该保存在 table 数组的哪个索引处。
这个方法非常巧妙,它通过 h & (table.length -1) 来得到该对象的保存位,而 HashMap 底层数组的长度总是 2 的n 次方,这是 HashMap 在速度上的优化。当 length 总是 2 的 n 次方时,h& (length-1) 运算等价于对 length 取模,也就是 h%length ,但是&比%具有更高的效率。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
下面举例说明下,n为table的长度。

添加一个元素put(K k,V v)
HashMap 允许K和V为 null,添加一个键值对时使用 put 方法,如果之前已经存在K的键值,那么旧值将会被新值替换。实现如下:
|
|
从上面代码可以看到 putVal() 方法的流程:
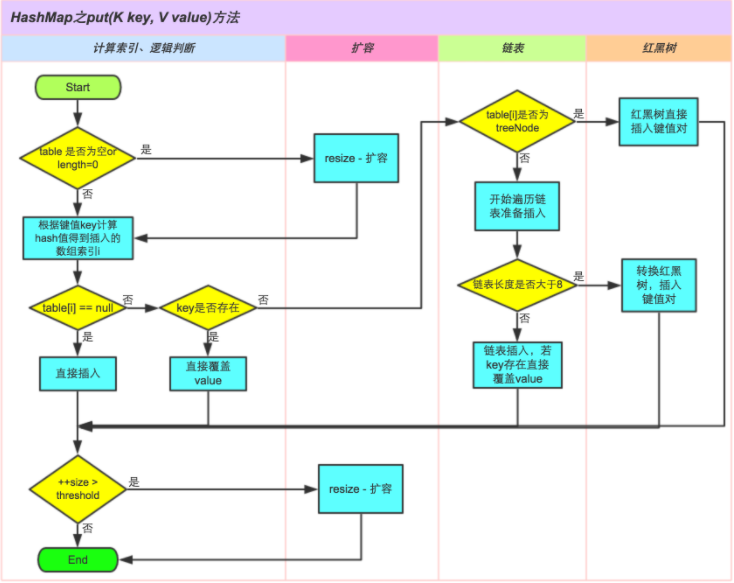
- 判断哈希表是否为空,如果为空,调用 resize() 方法进行创建哈希表
- 根据 hash 值得到哈希表中桶的头节点,如果为 null ,说明是第一个节点,直接调用 newNode() 方法添加节点即可
- 如果发生了哈希冲突,那么首先会得到头节点,比较是否相同,如果相同,则进行节点值的替换返回
- 如果头节点不相同,但是头节点已经是 TreeNode 了,说明该桶处已经是红黑树了,那么调用 putTreeVal() 方法将该结点加入到红黑树中
- 如果头节点不是 TreeNode,说明仍然是链表阶段,那么就需要从头开始遍历,一旦找到了相同的节点就跳出循环或者直到了链表尾部,那么将该节点插入到链表尾部
- 如果插入到链表尾部后,链表个数达到了阈值8,那么将会将该链表转换成红黑树,调用 treeifyBin() 方法
- 如果是新加一个数据,那么将 size+1,此时如果 size 超过了阈值,那么需要调用 resize() 方法进行扩容
resize()方法
下面我们一个一个分析上面提到的方法。首先是 resize() 方法,resize() 在哈希表为 null 时将会初始化,但是在已经初始化后就会进行容量扩展。下面是resize()的具体实现:
|
|
因为不像Java8之前的HashMap有初始化操作,此处选择将初始化和扩容放在了一起,并且又增加了红黑树的概念,所以导致整个方法的判断次数非常多,也是这个方法比较庞大的主要原因.
值得一体的是,在扩容后重新计算位置的时候,对链表进行优化,有兴趣可以搜索一下HashMap导致cpu百分之百的问题 而在Java中通过巧妙的进行&操作,然后获得高位是为0还是1.最终移动的位置就是低位的链表留在原地,高位的放在index+oldsize的地方就可以了,不用为每一个元素计算hash值,然后移动到对应的位置,再判断是否是链表,是否需要转换成树的操作.如下所示.
|
|
很容易知道这个&操作之后就是为0,因为oldcap都是2的倍数,只有高位为1,所以通过&确认高位要比%取余高效. 此时在看一下上面的扩容操作也许就更清晰了.
resize()首先获取新容量以及新阈值,然后根据新容量创建新表。如果是扩容操作,则需要进行rehash操作,通过e.hash&oldCap将链表分为两列,更好地均匀分布在新表中。
newNode()方法
下面介绍一些newNode方法.就是新建一个节点.可以思考一下为什么要把newNode抽离出来?
|
|
putTreeVal() 方法
添加节点到红黑树的方法是Java8中新添加的,需要满足链表的长度到8,才会转换成红黑树,其主要目的是防止某个下标处的链表太长,导致在找到的时候速度很慢,下面看一下实现
|
|
这里简单的梳理一下流程. 1.从根节点查找,找到了返回,如果没找到,找字节点 2.判断往哪个方向去查找 3.如果不存在,在子节点末端添加新节点
split() 方法
树的 split() 方法,主要是扩容操作,重新结算位置需要分裂树,之前讲过,扩容会根据和旧 map 容量进行&操作,移动高位为1的节点.并且验证新的节点列表是否需要重新转换成链表的形式.
当头节点是TreeNode时,将调用TreeNode的split方法将红黑树复制到新表中,代码实现如下:
|
|
TreeNode的split方法首先将头节点从头开始遍历,区分出两条单链表,再根据如果节点数小于等于6,那么将单链表的每个TreeNode转换成Node节点;否则将单链表转换成红黑树结构。
至此,resize()方法结束。需要注意的是rehash时,由于容量扩大一倍,本来一条链表有可能会分成两条链表,而如果将红黑树结构复制到新表时,有可能需要完成红黑树到单链表的转换。
treeifyBin()方法
treeifyBin()方法将表中某一个桶处的单链表结果转换成红黑树结构,其实现如下:
|
|
上述操作做了这些事:
- 根据哈希表中元素个数确定是扩容还是树形化
- 如果是树形化
- 遍历桶中的元素,创建相同个数的树形节点,复制内容,建立起联系
- 然后让桶第一个元素指向新建的树头结点,替换桶的链表内容为树形内容
treeify() 方法
但是我们发现,之前的操作并没有设置红黑树的颜色值,现在得到的只能算是个二叉树。在 最后调用树形节点 hd.treeify(tab) 方法进行塑造红黑树,来看看代码:
|
|
put操作总结
当调用put插入一个键值对时,在表为空时,会创建表。如果桶为空时,直接插入节点,如果桶不为空时,则需要对当前桶中包含的结构做判断,如果已是红黑树结构,那么需要使用红黑树的插入方法;如果不是红黑树结构,则需要遍历链表,如果添加到链表后端,如果该条链表达到了8,那么需要将该链表转换成红黑树,从treeifyBin方法可以看到,当容量小于64时,不会进行红黑树转换,只会扩容。当成功新加一个桶,那么需要将尺寸和阈值进行判断,是否需要进行resize()操作。
get(K k)操作
get(K k)根据键得到值,如果值不存在,那么返回null。其实现如下:
|
|
从上面代码可以看到getNode()方法中有多种情况:
\1. 表为空或表的长度为0或表中不存在key对应的hash值桶,那么返回null
\2. 如果表中有key对应hash值的桶,得到首节点,如果首节点匹配,那么直接返回;
\3. 如果首节点不匹配,并且没有后续节点,那么返回null
\4. 如果首节点有后续节点并且首节点是TreeNode,调用getTreeNode方法寻找节点
\5. 如果首节点有后续节点并且是链表结构,那么从前往后遍历,一旦找到则返回节点,否则返回null
remove()操作
remove(K k)用于根据键值删除键值对,如果哈希表中存在该键,那么返回键对应的值,否则返回null。其实现如下:
|
|
从上面的代码可以看出,removeNode()方法首先是找到待删除的节点,如果存在待删除节点,接下来再执行删除操作。查询时流程与getNode()方法的流程类似,只不过多了在遍历链表时还需要保存前驱节点,因为后面删除时要用到(单链表结构)。删除节点时就比较简单了,三种情况三种处理方式,分别是:
\1. 如果待删除节点是TreeNode,那么调用removeTreeNode()方法
\2. 如果待删除节点是Node,并且待删除节点就是头节点,那么将头节点更改为原有节点的下一个节点就可以了
\3. 如果待删除节点是Node且待删除节点不是头节点,那么将遍历过程中保存的前驱节点p的后继节点设为node的后继节点就可以了
红黑树中查找元素 getTreeNode()
HashMap 的查找方法是 get():
|
|
它通过计算指定 key 的哈希值后,调用内部方法 getNode();
|
|
这个 getNode() 方法就是根据哈希表元素个数与哈希值求模(使用的公式是 (n - 1) &hash)得到 key 所在的桶的头结点,如果头节点恰好是红黑树节点,就调用红黑树节点的 getTreeNode() 方法,否则就遍历链表节点。
|
|
getTreeNode 方法使通过调用树形节点的 find() 方法进行查找:
|
|
由于之前添加时已经保证这个树是有序的,因此查找时基本就是折半查找,效率很高。
这里和插入时一样,如果对比节点的哈希值和要查找的哈希值相等,就会判断 key 是否相等,相等就直接返回(也没有判断值哎);不相等就从子树中递归查找。
HashMap总结
至此,我们分析完了HashMap的主要方法:构造器、put、get和remove。只需要明白JDK1.8的HashMap底层结构,那么就很好理解了。需要注意的是什么时候应该将链表结构转换成红黑树结构,什么时候又应该将红黑树结构重新转换成链表结构,本文没有具体解释有关红黑树的结构,但是这并不影响理解HashMap的基本原理。
另外需要注意的是,本文的源码是基于JDK1.8的。

