
Java 8 ConcurrentHashMap 源码解读
ConcurrentHashMap 当之无愧是支持并发最好的键值对(Map)集合。在日常编码中,出场率也相当之高。在jdk8中,集合类 ConcurrentHashMap 经 Doug Lea 大师之手,借助volatile语义以及CAS操作进行优化,使得该集合类更好地发挥出了并发的优势。与jdk7中相比,在原有段锁(Segment)的基础上,引入了数组+链表+红黑树的存储模型,在查询效率上花费了不少心思。
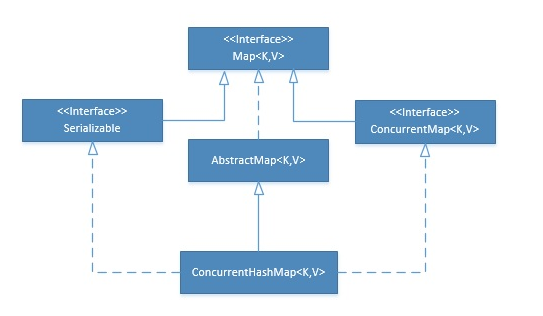
基础数据结构
ConcurrentHashMap内存存储结构图大致如下:
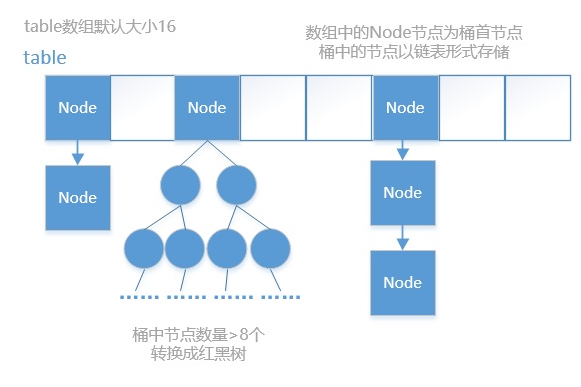
概述
1、设计首要目的:维护并发可读性(get、迭代相关);次要目的:使空间消耗比HashMap相同或更好,且支持多线程高效率的初始插入(empty table)。
2、HashTable线程安全,但采用synchronized,多线程下效率低下。线程1put时,线程2无法put或get。
阅前了解
在真正阅读 ConcurrentHashMap 源码之前,我们简单复习下关于volatile和CAS的概念,这样才能更好地帮助我们理解源码中的关键方法。
volatile语义
java提供的关键字volatile是最轻量级的同步机制。当定义一个变量为volatile时,它就具备了三层语义: - 可见性(Visibility):在多线程环境下,一个变量的写操作总是对其后的读取线程可见 - 原子性(Atomicity):volatile的读/写操作具有原子性 - 有序性(Ordering):禁止指令的重排序优化,JVM会通过插入内存屏障(Memory Barrier)指令来保证
就同步性能而言,大多数场景下volatile的总开销是要比锁低的。在ConcurrentHashMap的源码中,我们能看到频繁的volatile变量读取与写入。
CAS操作
CAS一般被理解为原子操作。在java中,正是利用了处理器的CMPXCHG(intel)指令实现CAS操作。CAS需要接受原有期望值expected以及想要修改的新值x,只有在原有期望值与当前值相等时才会更新为x,否则为失败。在ConcurrentHashMap的方法中,大量使用CAS获取/修改互斥量,以达到多线程并发环境下的正确性。
ConcurrentHashMap 的常量
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ConcurrentHashMap 重要属性
Node
Key-value entry, 继承自Map.Entry<K,V>对象。
Node<K,V>节点是ConcurrentHashMap存储数据的最基本结构。一个数据mapping节点中,存储4个变量:当前节点hash值、节点的key值、节点的value值、指向下一个节点的指针next。其中在子类中的hash可以为负数,具有特殊的并发处理意义,后文会解释。除了具有特殊意义的子类,Node中的key和val不允许为null。
|
|
另外可以看出很多属性都是用volatile进行修饰的,也就是为了保证内存可见性。
- 这个Node内部类与HashMap中定义的Node类很相似,但是有一些差别
- 它对value和next属性设置了volatile同步锁
- 它不允许调用setValue方法直接改变Node的value域
- 它增加了find方法辅助map.get()方法
TreeNode
Node的子类,红黑树节点,当Node链表过长时,会转换成红黑树。
位于 ConcurrentHashMap 类的 2653行 或 搜索 / —————- TreeNodes ————– /
|
|
树节点,继承于承载数据的Node类。而红黑树的操作是针对TreeBin类的,从该类的注释也可以看出,也就是TreeBin会将TreeNode进行再一次封装
TreeBin
位于 ConcurrentHashMap 类的 2709 行 或 搜索 / —————- TreeBins ————– /
|
|
这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象。
threeifyBin
位于 ConcurrentHashMap 类的 2611 行 或 搜索 “private final void treeifyBin”
|
|
ForwardingNode
位于 ConcurrentHashMap 类的 2163 行 或 搜索 “static final class ForwardingNode”
|
|
在扩容时才会出现的特殊节点,其key,value,hash全部为null。并拥有nextTable指针引用新的table数组。
Traverser
|
|
tryPresize(扩容)
协调多个线程如何调用transfer方法进行hash桶的迁移(addCount,helpTransfer 方法中也有类似的逻辑)
tryPresize在putAll以及treeifyBin中调用
|
|
|
|
spread 重新哈希
spread()重哈希,以减小Hash冲突。我们知道对于一个hash表来说,hash值分散的不够均匀的话会大大增加哈希冲突的概率,从而影响到hash表的性能。因此通过spread方法进行了一次重hash从而大大减小哈希冲突的可能性。spread方法为:
|
|
该方法主要是将key的hashCode的低16位于高16位进行异或运算,这样不仅能够使得hash值能够分散能够均匀减小hash冲突的概率,另外另外只用到了异或运算,在性能开销上也能兼顾,做到平衡的trade-off。
get(查找)
|
|
代码的逻辑请看注释,首先先看当前的hash桶数组节点即table[i]是否为查找的节点,若是则直接返回;若不是,则继续再看当前是不是树节点?通过看节点的hash值是否为小于0,如果小于0则为树节点。如果是树节点在红黑树中查找节点;如果不是树节点,那就只剩下为链表的形式的一种可能性了,就向后遍历查找节点,若查找到则返回节点的value即可,若没有找到就返回null。
这个 get 请求,我们需要 cas 来保证变量的原子性。如果 tab[i] 正被锁住,那么 CAS 就会失败,失败之后就会不断的重试。这也保证了在高并发情况下不会出错。
我们来分析一下哪些情况会导致 get 在并发的情况下可能取不到值。
- 一个线程在 get 的时候,另一个线程在对同一个 key 的 node 进行 remove 操作
- 一个线程在 get 的时候,另一个线程正在重排 table 。可能导致旧 table 取不到值
那么本质是,我在get的时候,有其他线程在对同一桶的链表或树进行修改。那么get是怎么保证同步性的呢?我们看到e = tabAt(tab, (n - 1) & h)) != null,在看下tablAt到底是干嘛的:
|
|
它是对tab[i]进行原子性的读取,因为我们知道putVal等对table的桶操作是有加锁的,那么一般情况下我们对桶的读也是要加锁的,但是我们这边为什么不需要加锁呢?因为我们用了Unsafe的getObjectVolatile,因为table是volatile类型,所以对tab[i]的原子请求也是可见的。因为如果同步正确的情况下,根据happens-before原则,对volatile域的写入操作happens-before于每一个后续对同一域的读操作。所以不管其他线程对table链表或树的修改,都对get读取可见。用一张图说明,协调读-写线程可见示意图:
jdk7是没有用到CAS操作和Unsafe类的,下面是jdk7的get方法:
|
|
为什么我们在get的时候需要判断count不等于0呢?如果是在HashMap的源码中是没有这个判断的,不用判断不是也是可以的吗?这个就是用到线程安全发布情况下happens-before原则之volatile变量法则:对volatile域的写入操作happens-before于每一个后续对同一域的读操作,看下面的示意图:
tabAt
以 volatile 读的方式读取 table 数组中的元素
|
|
tabAt 方法用来获取table数组中索引为i的Node元素。
put/putVal
putVal是将一个新key-value mapping插入到当前ConcurrentHashMap的关键方法。
此方法的具体流程如下图:
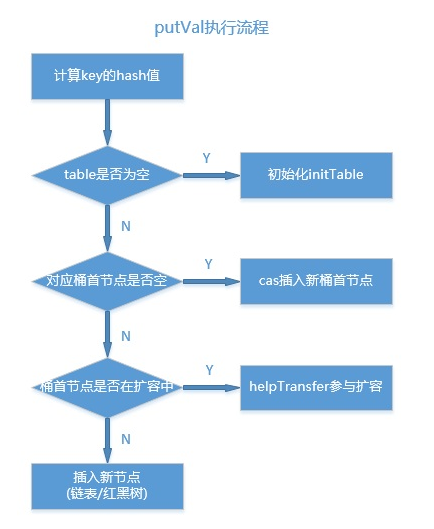
|
|
当table[i]为链表的头结点,在链表中插入新值在table[i]不为null并且不为forwardingNode时,并且当前Node f的hash值大于0(fh >= 0)的话说明当前节点f为当前桶的所有的节点组成的链表的头结点。那么接下来,要想向ConcurrentHashMap插入新值的话就是向这个链表插入新值。通过synchronized (f)的方式进行加锁以实现线程安全性。往链表中插入节点的部分代码为:
|
|
这部分代码很好理解,就是两种情况:1. 在链表中如果找到了与待插入的键值对的key相同的节点,就直接覆盖即可;2. 如果直到找到了链表的末尾都没有找到的话,就直接将待插入的键值对追加到链表的末尾即可。
当table[i]为红黑树的根节点,在红黑树中插入新值按照之前的数组+链表的设计方案,这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,甚至在极端情况下,查找一个节点会出现时间复杂度为O(n)的情况,则会严重影响ConcurrentHashMap的性能,于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高ConcurrentHashMap的性能,其中会用到红黑树的插入、删除、查找等算法。当table[i]为红黑树的树节点时的操作为:
|
|
首先在if中通过f instanceof TreeBin判断当前table[i]是否是树节点,这下也正好验证了我们在最上面介绍时说的TreeBin会对TreeNode做进一步封装,对红黑树进行操作的时候针对的是TreeBin而不是TreeNode。这段代码很简单,调用putTreeVal方法完成向红黑树插入新节点,同样的逻辑,如果在红黑树中存在于待插入键值对的Key相同(hash值相等并且equals方法判断为true)的节点的话,就覆盖旧值,否则就向红黑树追加新节点。
当table[i]为红黑树的根节点,在红黑树中插入新值。按照之前的数组+链表的设计方案,这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,甚至在极端情况下,查找一个节点会出现时间复杂度为O(n)的情况,则会严重影响ConcurrentHashMap的性能,于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高ConcurrentHashMap的性能,其中会用到红黑树的插入、删除、查找等算法。当table[i]为红黑树的树节点时的操作为:
|
|
首先在if中通过f instanceof TreeBin判断当前table[i]是否是树节点,这下也正好验证了我们在最上面介绍时说的TreeBin会对TreeNode做进一步封装,对红黑树进行操作的时候针对的是TreeBin而不是TreeNode。这段代码很简单,调用putTreeVal方法完成向红黑树插入新节点,同样的逻辑,如果在红黑树中存在于待插入键值对的Key相同(hash值相等并且equals方法判断为true)的节点的话,就覆盖旧值,否则就向红黑树追加新节点。
根据当前节点个数进行调整当完成数据新节点插入之后,会进一步对当前链表大小进行调整,这部分代码为:
|
|
很容易理解,如果当前链表节点个数大于等于8(TREEIFY_THRESHOLD)的时候,就会调用treeifyBin方法将tabel[i](第i个散列桶)拉链转换成红黑树。
关于Put方法的逻辑就基本说的差不多了,现在来做一些总结:
整体流程:
- 首先对于每一个放入的值,首先利用spread方法对key的hashcode进行一次hash计算,由此来确定这个值在 table中的位置;
- 如果当前table数组还未初始化,先将table数组进行初始化操作;
- 如果这个位置是null的,那么使用CAS操作直接放入;
- 如果这个位置存在结点,说明发生了hash碰撞,首先判断这个节点的类型。如果该节点fh==MOVED(代表forwardingNode,数组正在进行扩容)的话,说明正在进行扩容;
- 如果是链表节点(fh>0),则得到的结点就是hash值相同的节点组成的链表的头节点。需要依次向后遍历确定这个新加入的值所在位置。如果遇到hash值与key值都与新加入节点是一致的情况,则只需要更新value值即可。否则依次向后遍历,直到链表尾插入这个结点;
- 如果这个节点的类型是TreeBin的话,直接调用红黑树的插入方法进行插入新的节点;
- 插入完节点之后再次检查链表长度,如果长度大于8,就把这个链表转换成红黑树;
- 对当前容量大小进行检查,如果超过了临界值(实际大小*加载因子)就需要扩容。
该流程中,可以细细品味的环节有: - 初始化方法 initTable - 扩容方法 transfer (在多线程扩容方法 helpTransfer 中被调用)
initTable
initTable方法允许多线程同时进入,但只有一个线程可以完成table的初始化,其他线程都会通过yield方法让出cpu。
|
|
代码的逻辑请见注释,有可能存在一个情况是多个线程同时走到这个方法中,为了保证能够正确初始化,在第1步中会先通过if进行判断,若当前已经有一个线程正在初始化即sizeCtl值变为-1,这个时候其他线程在If判断为true从而调用Thread.yield()让出CPU时间片。正在进行初始化的线程会调用U.compareAndSwapInt方法将sizeCtl改为-1即正在初始化的状态。另外还需要注意的事情是,在第四步中会进一步计算数组中可用的大小即为数组实际大小n乘以加载因子0.75.可以看看这里乘以0.75是怎么算的,0.75为四分之三,这里n - (n >>> 2)是不是刚好是n-(1/4)n=(3/4)n,挺有意思的吧:)。如果选择是无参的构造器的话,这里在new Node数组的时候会使用默认大小为DEFAULT_CAPACITY(16),然后乘以加载因子0.75为12,也就是说数组的可用大小为12。
casTabAt(原子操作方法)
以 CAS 的方式,将元素插入到 table 数组
|
|
利用CAS操作设置table数组中索引为i的元素
setTabAt
以 valatile 写的方式,将元素插入 table 数组
|
|
该方法用来设置table数组中索引为i的元素
实例构造器方法
在使用ConcurrentHashMap第一件事自然而然就是new 出来一个ConcurrentHashMap对象,一共提供了如下几个构造器方法:
|
|
ConcurrentHashMap一共给我们提供了5中构造器方法,具体使用请看注释,我们来看看第2种构造器,传入指定大小时的情况,该构造器源码为:
|
|
这段代码的逻辑请看注释,很容易理解,如果小于0就直接抛出异常,如果指定值大于了所允许的最大值的话就取最大值,否则,在对指定值做进一步处理。最后将cap赋值给sizeCtl,关于sizeCtl的说明请看上面的说明,当调用构造器方法之后,sizeCtl的大小应该就代表了ConcurrentHashMap的大小,即table数组长度。tableSizeFor做了哪些事情了?源码为:
tableSizeFor
|
|
通过注释就很清楚了,该方法会将调用构造器方法时指定的大小转换成一个2的幂次方数,也就是说ConcurrentHashMap的大小一定是2的幂次方,比如,当指定大小为18时,为了满足2的幂次方特性,实际上concurrentHashMapd的大小为2的5次方(32)。另外,需要注意的是,调用构造器方法的时候并未构造出table数组(可以理解为ConcurrentHashMap的数据容器),只是算出table数组的长度,当第一次向ConcurrentHashMap插入数据的时候才真正的完成初始化创建table数组的工作。
helpTransfer(协助扩容)
|
|
addCount
在put方法结尾处调用了addCount方法,把当前ConcurrentHashMap的元素个数+1这个方法一共做了两件事,更新baseCount的值,检测是否进行扩容。
|
|
看上面的注释1,每次都会对 baseCount 加1,如果并发竞争太大,那么可能导致 U.compareAndSwapLong(this,BASECOUNT,b=baseCount,s = b + x) 失败,那么为了提高高并发的时候 baseCount 可见性的失败的问题,又避免一直重试,这样性能会有很大的影响,那么在 jdk 8的时候是有引入一个类 Striped64 ,其中 LongAdder 和 DoubleAdder 就是对这个类的实现。这两个方法都是为了解决高并发场景而生的,是 AtomicLong 的加强版,AtomicLong 在高并发场景性能会比 LongAdder 差。但是 LongAdder 的空间复杂度会高点。
fullAddCount
|
|
回到 addCount 来,我们每次竞争都对 baseCount 进行加 1 当达到一定的容量时,就需要对 table 进行扩容。 使用 transfer 方法。
transfer
负责迁移node节点
扩容transfer方法是一个设计极为精巧的方法。通过互斥读写ForwardingNode,多线程可以协同完成扩容任务。
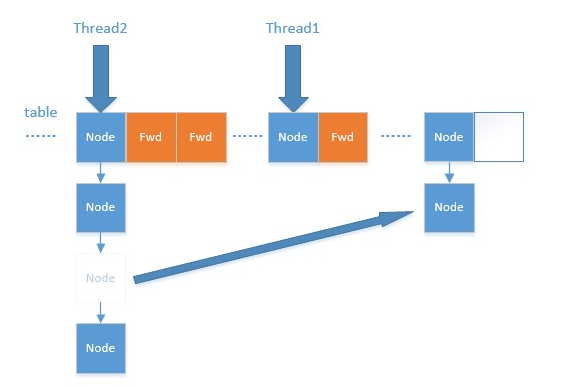
|
|
代码逻辑请看注释,整个扩容操作分为两个部分:
第一部分是构建一个nextTable,它的容量是原来的两倍,这个操作是单线程完成的。新建table数组的代码为:Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1],在原容量大小的基础上右移一位。
第二个部分就是将原来table中的元素复制到nextTable中,主要是遍历复制的过程。
根据运算得到当前遍历的数组的位置i,然后利用tabAt方法获得i位置的元素再进行判断:
- 如果这个位置为空,就在原table中的i位置放入forwardNode节点,这个也是触发并发扩容的关键点;
- 如果这个位置是Node节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上
- 如果这个位置是TreeBin节点(fh<0),也做一个反序处理,并且判断是否需要untreefi,把处理的结果分别放在nextTable的i和i+n的位置上
- 遍历过所有的节点以后就完成了复制工作,这时让nextTable作为新的table,并且更新sizeCtl为新容量的0.75倍 ,完成扩容。设置为新容量的0.75倍代码为
sizeCtl = (n << 1) - (n >>> 1),仔细体会下是不是很巧妙,n<<1相当于n右移一位表示n的两倍即2n,n>>>1左右一位相当于n除以2即0.5n,然后两者相减为2n-0.5n=1.5n,是不是刚好等于新容量的0.75倍即2n*0.75=1.5n。最后用一个示意图来进行总结(图片摘自网络):
mappingCount 与 size
mappingCount与size方法的类似 从给出的注释来看,应该使用mappingCount代替size方法 两个方法都没有直接返回basecount 而是统计一次这个值,而这个值其实也是一个大概的数值,因此可能在统计的时候有其他线程正在执行插入或删除操作。
|
|
remove
和put方法一样,多个remove线程请求不同的hash桶时,可以并发执行

如图所示:删除的node节点的next依然指着下一个元素。此时若有一个遍历线程正在遍历这个已经删除的节点,这个遍历线程依然可以通过next属性访问下一个元素。从遍历线程的角度看,他并没有感知到此节点已经删除了,这说明了ConcurrentHashMap提供了弱一致性的迭代器。
|
|
ForwardingNode
|
|
总结
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
而在1.8的时候摒弃了segment臃肿的设计,这种设计在定位到具体的桶时,要先定位到具体的segment,然后再
在segment中定位到具体的桶。而到了1.8的时候是针对的是Node[] tale数组中的每一个桶,进一步减小了锁粒度。并且防止拉链过长导致性能下降,当链表长度大于8的时候采用红黑树的设计。
主要设计上的变化有以下几点:
- 不采用segment而采用node,锁住node来实现减小锁粒度。
- 设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
- 使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
- sizeCtl的不同值来代表不同含义,起到了控制的作用。
- 采用synchronized而不是ReentrantLock
- volatile语义提供更细颗粒度的轻量级锁,使得多线程可以(几乎)同时读写实例中的关键量,正确理解当前类所处的状态,进入对应if语句中执行相关逻辑。
- 采用更加细粒度的hash桶级别锁,扩容期间,依然可以保证写操作的并发度。
- 多线程无锁扩容的关键就是通过CAS设置sizeCtl与transferIndex变量,协调多个线程对table数组中的node进行迁移。
参考文章:http://www.cnblogs.com/huaizuo/p/5413069.html
参考文章:http://www.bijishequ.com/detail/560964?p=
参考文章:https://bentang.me/tech/2016/12/01/jdk8-concurrenthashmap-1/
参考文章: http://www.jianshu.com/p/5bc70d9e5410
扩容原理: http://www.jianshu.com/p/487d00afe6ca
遍历操作:http://www.jianshu.com/p/3e85ac8f8662

