Python 常用的内置函数
如果你遇到一个需求,且你认为这个需求很普遍,先想想有没有什么内置函数可以使用(BIF)。另外要记住:Python 3 包含 70 多个 BIF ,所以有大量现成的功能等着你来发现。
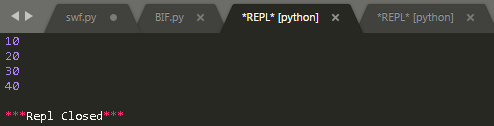
list()
这是一个工厂函数,创建一个新的空列表。
|
|
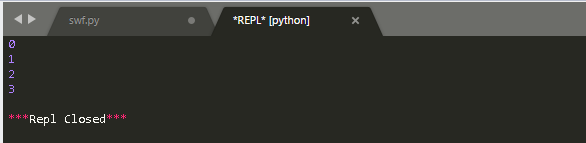
range()
range() BIF 迭代固定次数。
可以提供你需要的控制来迭代指定的次数,而且可以用来生成一个从 0 直到(但不包含)某个数的数字列表。
一下是这个 BIF 的用法:
|
|
F5 运行程序
enumerate()
创建成对数据的一个编码列表,从 0 开始
先来做一个对比:
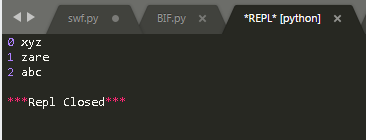
法1: 使用 range() 和 len() 来实现
|
|
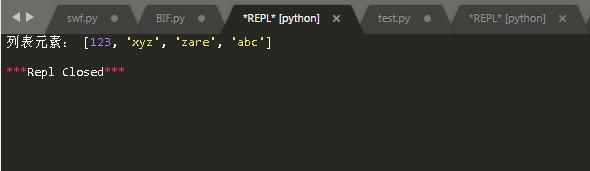
法2:使用enumerate () 来实现
|
|
enumerate会将数组或列表组成一个索引序列。使我们再获取索引和索引内容的时候更加方便。
int()
int()函数的作用是将一个数字或base类型的字符串转换成整数。
函数原型 int(x, base=10),base缺省值为10,也就是说不指定base的值时,函数将x按十进制处理。
注意:
- x 可以是数字或字符串,但是base被赋值后 x 只能是字符串
- x 作为字符串时必须是 base 类型,也就是说 x 变成数字时必须能用 base 进制表示
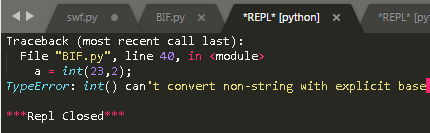
【1】 x 是数字的情况:
|
|
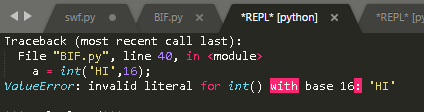
【2】x 是字符串的情况:
|
|
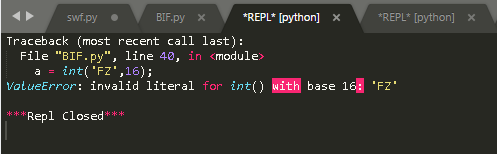
【3】 base 可取值范围是 2~36,囊括了所有的英文字母(不区分大小写),十六进制中F表示15,那么G将在二十进制中表示16,依此类推….Z在三十六进制中表示35
|
|
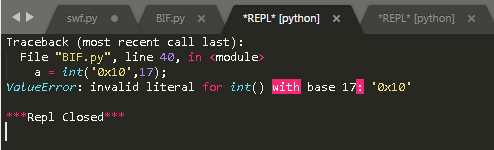
【4】字符串 0x 可以出现在十六进制中,视作十六进制的符号,同理 0b 可以出现在二进制中,除此之外视作数字 0 和字母 x
|
|
id()
id(object)函数是返回对象object在其生命周期内位于内存中的地址,id函数的参数类型是一个对象。
注意:
我们需要明确一点就是在Python中一切皆对象,变量中存放的是对象的引用。这个确实有点难以理解,“一切皆对象”?对,在Python中确实是这样,包括我们之前经常用到的字符串常量,整型常量都是对象。
|
|
这段代码的运行结果:
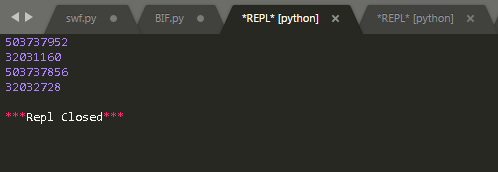
|
|
运行结果:
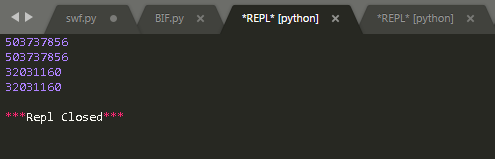
结果说明:对于这个语句id(2)没有报错,就可以知道2在这里是一个对象。id(x)和id(2)的值是一样的,id(y)和id(‘hello’)的值也是一样的。
|
|
运行结果:
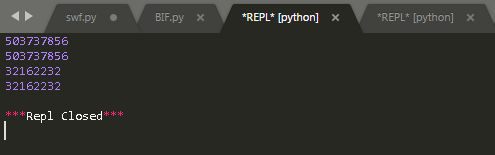
结果说明:id(x)和id(y)的结果是相同的,id(s)和id(t)的结果也是相同的。这说明x和y指向的是同一对象,而t和s也是指向的同一对象。x=2这句让变量x指向了int类型的对象2,而y=2这句执行时,并不重新为2分配空间,而是让y直接指向了已经存在的int类型的对象2.这个很好理解,因为本身只是想给y赋一个值2,而在内存中已经存在了这样一个int类型对象2,所以就直接让y指向了已经存在的对象。这样一来不仅能达到目的,还能节约内存空间。t=s这句变量互相赋值,也相当于是让t指向了已经存在的字符串类型的对象’hello’。
看这幅图就理解了:

|
|
运行结果:
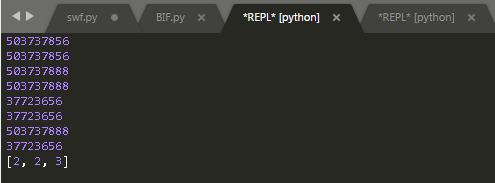
结果分析:两次的id(x)的值不同,这个可能让人有点难以理解。注意,在Python中,单一元素的对象是不允许更改的,比如整型数据、字符串、浮点数等。x=3这句的执行过程并不是先获取x原来指向的对象的地址,再把内存中的值更改为3,而是新申请一段内存来存储对象3,再让x去指向对象3,所以两次id(x)的值不同。然而为何改变了L中的某个子元素的值后,id(L)的值没有发生改变?在Python中,复杂元素的对象是允许更改的,比如列表、字典、元组等。Python中变量存储的是对象的引用,对于列表,其id()值返回的是列表第一个子元素L[0]的存储地址。就像上面的例子,L=[1,2,3],这里的L有三个子元素L[0],L[1],L[2],L[0]、L[1]、L[2]分别指向对象1、2、3,id(L)值和对象3的存储地址相同.
看下面这个图就明白了:

因为L和M指向的是同一对象,所以在更改了L中子元素的值后,M也相应改变了,但是id(L)值并没有改变,因为这句L[0]=2只是让L[0]重新指向了对象2,而L[0]本身的存储地址并没有发生改变,所以id(L)的值没有改变( id(L)的值实际等于L[0]本身的存储地址)。
next()
next()函数返回迭代器的下一个元素
|
|
运行结果: