
lucene(10)—lucene搜索之联想词提示之suggest原理和应用
昨天了解了suggest包中的spell相关的内容,主要是拼写检查和相似度查询提示;
今天准备了解下关于联想词的内容,lucene的联想词是在org.apache.lucene.search.suggest包下边,提供了自动补全或者联想提示功能的支持;
InputIterator说明
InputIterator是一个支持枚举term,weight,payload三元组的供suggester使用的接口,目前仅支持AnalyzingSuggester,FuzzySuggester andAnalyzingInfixSuggester 三种suggester支持payloads;
InputIterator的实现类有以下几种:
BufferedInputIterator:对二进制类型的输入进行轮询;
DocumentInputIterator:从索引中被store的field中轮询;
FileIterator:从文件中每次读出单行的数据轮询,以\t进行间隔(且\t的个数最多为2个);
HighFrequencyIterator:从索引中被store的field轮询,忽略长度小于设定值的文本;
InputIteratorWrapper:遍历BytesRefIterator并且返回的内容不包含payload且weight均为1;
SortedInputIterator:二进制类型的输入轮询且按照指定的comparator算法进行排序;
InputIterator提供的方法如下:
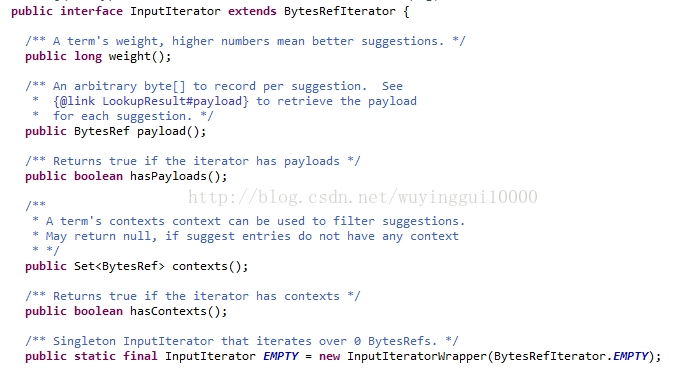
weight():此方法设置某个term的权重,设置的越高suggest的优先级越高;
payload():每个suggestion对应的元数据的二进制表示,我们在传输对象的时候需要转换对象或对象的某个属性为BytesRef类型,相应的suggester调用lookup的时候会返回payloads信息;
hasPayload():判断iterator是否有payloads;
contexts():获取某个term的contexts,用来过滤suggest的内容,如果suggest的列表为空,返回null
hasContexts():获取iterator是否有contexts;
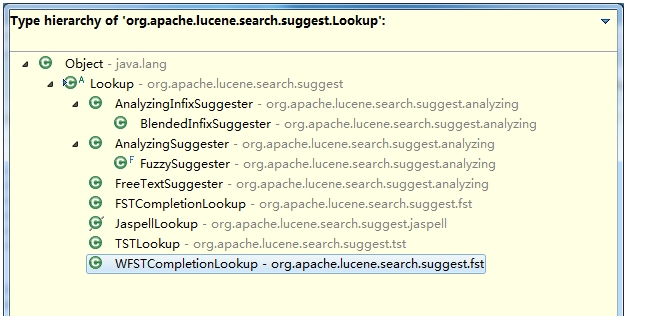
Suggester查询工具Lookup类说明
此类提供了字符串的联想查询功能
Lookup类提供了一个CharSequenceComparator,此comparator主要是用来对CharSequence进行排序,按字符顺序排序;
内置LookupResult,用于返回suggest的结果,同时也是按照CharSequenceComparator进行key的排序;
内置了LookupPriorityQueue,用以存储LookupResult;
LookUp提供的方法
build(Dictionary dict) : 从指定directory进行build;
load(InputStream input) : 将InputStream转成DataInput并执行load(DataInput)方法;
store(OutputStream output) : 将OutputStream转成DataOutput并执行store(DataOutput)方法;
getCount() : 获取lookup的build的项的数量;
build(InputIterator inputIterator) : 根据指定的InputIterator构建Lookup对象;
lookup(CharSequence key, boolean onlyMorePopular, int num) :根据key查询可能的结果返回值为List
Lookup的相关实现如下:
编写自己的suggest模块
注意:在suggest的时候我们需要导入lucene-misc-5.1.0.jar否则系统会提示类SortedMergePolicy没有找到;
首先我们定义自己的实体类:
|
|
然后定义InputIterator这里定义消费者是List
|
|
编写测试类
|
|

