
lucene(7)—lucene搜索之IndexSearcher构建过程
IndexSearcher
搜索引擎的构建分为索引内容和查询索引两个大方面,这里要介绍的是lucene索引查询器即IndexSearcher的构建过程;
首先了解下IndexSearcher:
- IndexSearcher提供了对单个IndexReader的查询实现;
- 我们对索引的查询,可以通过调用search(Query,n)或者search(Query,Filter,n)方法;
- 在索引内容变动不大的情况下,我们可以对索引的搜索采用单个IndexSearcher共享的方式来提升性能;
- 如果索引有变动,我们就需要使用DirectoryReader.openIfChanged(DirectoryReader)来获取新的reader,然后创建新的IndexSearcher对象;
- 为了使查询延迟率低,我们最好使用近实时搜索的方法(此时我们的DirectoryReader的构建就要采用
DirectoryReader.open(IndexWriter, boolean)) - IndexSearcher实例是完全线程安全的,这意味着多个线程可以并发调用任何方法。如果需要外部同步,无需添加IndexSearcher的同步;
IndexSearcher的创建过程
根据索引文件路径创建FSDirectory的实例,返回的FSDirectory实例跟系统或运行环境有关,对于Linux, MacOSX, Solaris, and Windows 64-bit JREs返回的是一个MMapDirectory实例,对于其他非windows JREs环境返回的是NIOFSDirectory,而对于其他Windows的JRE环境返回的是SimpleFSDirectory,其执行效率依次降低
接着DirectoryReader根据获取到的FSDirectory实例读取索引文件并得到DirectoryReader对象;DirectoryReader的open方法返回实例的原理:读取索引目录中的Segments文件内容,倒序遍历SegmentInfos并填充到SegmentReader(IndexReader的一种实现)数组,并构建StandardDirectoryReader的实例
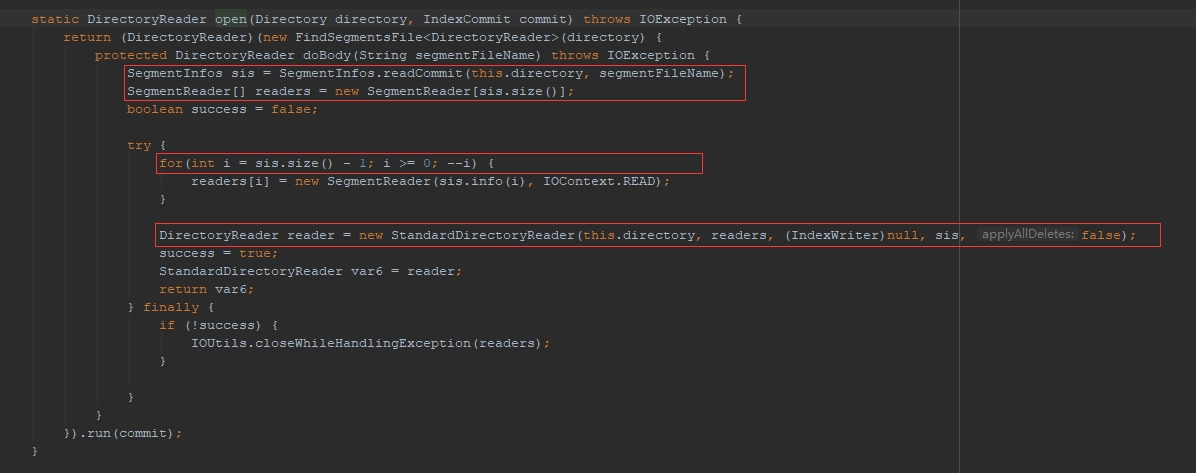
有了IndexReader,IndexSearcher对象实例化就手到拈来了,new IndexSearcher(DirectoryReader)就可以得到其实例;如果我们想提高IndexSearcher的执行效率可以new IndexSearcher(DirecotoryReader,ExcuterService)来创建IndexSearcher对象,这样做的好处为对每块segment采用了分工查询,但是要注意IndexSearcher并不维护ExcuterService的生命周期,我们还需要自行调用ExcuterService的close/awaitTermination
相关实践
以下是根据IndexSearcher相关的构建过程及其特性编写的一个搜索的工具类
|
|

