
lucene(8)—lucene搜索之索引的查询原理和查询工具类(支持分页)示例
IndexSearcher常用方法
IndexSearcher提供了几个常用的方法:
- IndexSearcher.doc(int docID) 获取索引文件中的第n个索引存储的相关字段,返回为Document类型,可以据此读取document中的Field.STORE.YES的字段;
- IndexSearcher.doc(int docID, StoredFieldVisitor fieldVisitor) 获取StoredFieldVisitor指定的字段的document,StoredFieldVisitor定义如下
|
|
- IndexSearcher.doc(int docID, Set
fieldsToLoad) 此方法同上边的IndexSearcher.doc(int docID, StoredFieldVisitor fieldVisitor) ,其实现如下图

IndexSearcher.count(Query query) 统计符合query条件的document个数
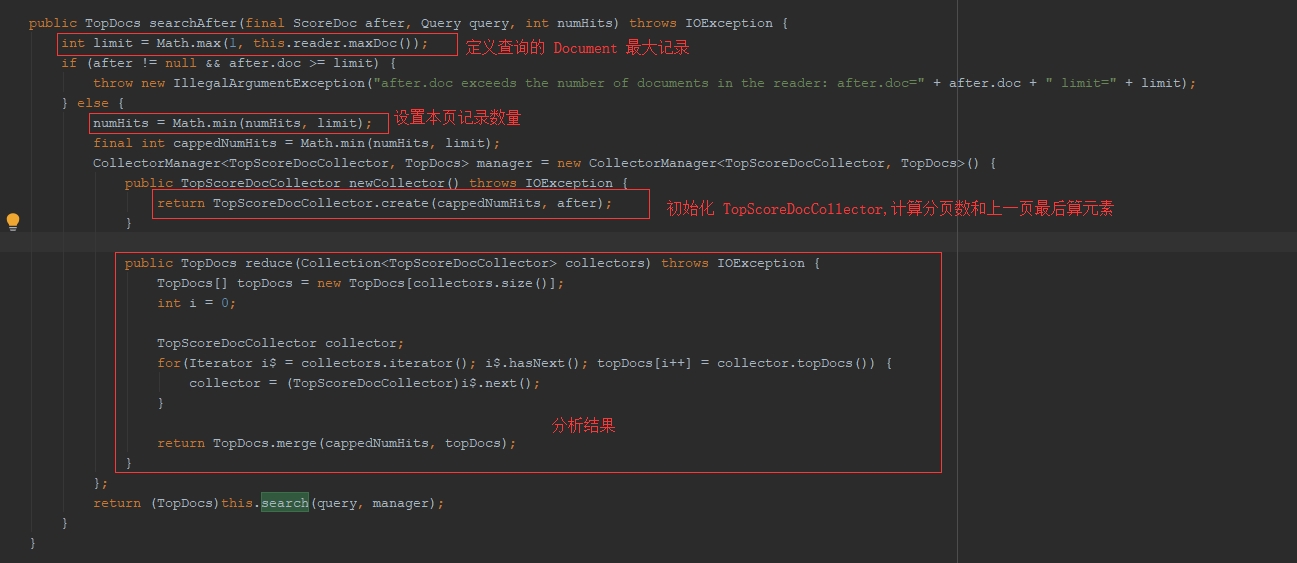
IndexSearcher.searchAfter(final ScoreDoc after, Query query, int numHits) 此方法会返回符合query查询条件的且在after之后的numHits条记录;
其实现原理为:
先读取当前索引文件的最大数据条数limit,然后判断after是否为空和after对应的document的下标是否超出limit的限制,如果超出的话抛出非法的参数异常;
设置读取的条数为numHits和limit中最小的(因为有超出最大条数的可能,避免超出限制而造成的异常)
接下来创建一个CollectorManager类型的对象,该对象定义了要返回的TopDocs的个数,上一页的document的结尾(after),并且对查询结果进行分析合并
最后调用search(query,manager)来查询结果
IndexSearcher.search(Query query, int n) 查询符合query条件的前n个记录
- IndexSearcher.search(Query query, Collector results) 查询符合collector的记录,collector定义了分页等信息
- IndexSearcher.search(Query query, int n,Sort sort, boolean doDocScores, boolean doMaxScore) 实现任意排序的查询,同时控制是否计算hit score和max score是否被计算在内,查询前n条符合query条件的document;
IndexSearcher.search(Query query, CollectorManager<C, T> collectorManager) 利用给定的collectorManager获取符合query条件的结果,其执行流程如下:
先判断是否有ExecutorService执行查询的任务,如果没有executor,IndexSearcher会在单个任务下进行查询操作;
如果IndexSearcher有executor,则会由每个线程控制一部分索引的读取,而且查询的过程中采用的是future机制,此种方式是边读边往结果集里边追加数据,这种异
步的处理机制也提升了效率,其执行过程如下:

编码实践
我中午的时候写了一个SearchUtil的工具类,里边添加了多目录查询和分页查询的功能,经测试可用,工具类和测试的代码如下:
|
|
相关测试代码如下:
|
|
代码下载
代码下载请点击http://download.csdn.net/detail/wuyinggui10000/8703165,运行时请先运行IndexTest类进行索引的创建~!

