第2章程序设计语言基础知识
程序设计语言概述
程序设计语言的基本概念
低级语言和高级语言
机器语言和汇编语言为高级语言。在此基础上,人们开发了功能更强、抽象级别更高的语言以支持程序设计,于是产生了面向各类应用程序的程序设计语言,称为高级语言。ge:Java、C、C++、PHP、Python等。
编译程序和解释程序
语言之间的翻译方式有:汇编、解释和编译。
解释程序也称为解释器,它或者直接解释执行源程序,或者将源程序翻译成某种中间代码后再加以执行。
编译程序(编译器)则是将源程序翻译成目标语言程序,然后再计算机上运行目标程序。
根本区别:编译方式下,编译器则将源程序翻译成独立保存的目标程序。在解释程序下,翻译源程序时不生成独立的目标程序。
程序设计语言的定义
程序设计语言的定义都涉及语法、语义和语用。
语法是指由程序设计语言的基本符号组成程序中的各个语法成分(包含程序)的一组规则,其中由基本字符构成的符号(单词)书写规则称为词法规则,由符号构成语法成分的规则称为语法规则。程序设计语言的语法可用形式语言进行描述。
语义是程序设计语言中按语法规则构成的各个语法成分的含义,可分为静态语义和动态语义。静态语义指编译时可以确定的语法成分的含义,而运行时才能确定的含义是动态语义。一个程序的执行效果说明了该程序的语义,它取决于构成程序的各个组成部分和语义。
语用表示了构成语言的各个记号和使用者的关系,涉及符号的来源、使用和影响。
语言的实现则有语境问题。语境是指理解和实现程序设计语言的环境,包括编译环境和运行环境。
程序设计语言分类
程序设计语言发展概述
| 语言名称 | 概述 |
|---|---|
| Fortran | 第一个被广泛用来进行科学和工程计算的高级语言。 |
| ALGOL | 为软件自动及软件可靠性的发展墓定了基础 |
| PASCAL | 是一种过程式、结构化程序设计语言 |
| C 语言 | 20世纪70年代初发展起来的一种通用程序设计语言 |
| C++ | 基于C语言发展起来的,比C多了封装和抽象,增加了类机制是C++成为面向对象程序设计语言 |
| C# | 由 Microsoft 公司开发的一种面向对象语言,较于C++它在许多方面进行了限制和增强 |
| Objective-C | 根据C衍生出来的语言,与 C# 类似,它仅支持单一父类继承,不支持多重继承 |
| Java | 产生于20世纪70年代,保留了 C++ 的基本语法、类和继承等概念,与 C++ 相比,其语法和语义更合理 |
| Ruby | 约1993年设计的一种解释性、面向对象、动态类型的脚本语言。 |
| PHP | 是一种在服务器端执行的、嵌入 HTML 文档的脚本语言,语言风格类似于 C 语言,由网站编程人员广泛运用。它可以快速的执行动态网页,其语法混了C、Java、Perl以及 PHP 自创的语法。由于在服务器端执行,PHP 能充分利用服务器的性能。PHP 支持几乎所有流行的数据库以及操作系统。 |
| Python | 是一种面向对象的解释型程序设计语言,可用于编写独立程序、快速脚本和复杂应用的原型。Python 也是一种脚本语言,它支持多操作系统的底层访问,也可以将 Python 源程序翻译成字节码在 Python 虚拟机上运行。虽然 Python 的内核很小,但它提供了丰富的基本构建块,还可以用 C、C++ 和 Java 等进行扩展,因此可以用它开发任何类型的程序。 |
| Java Script | 是一种脚本语言,被广泛用于 Web 应用开发。通常,将 Java Script 脚本嵌入到 HTML 中来实现自身的功能 |
| Delphi | 是一种可视化开发工具,主要特性是基于窗体和面向对象的方法、高速的编译器、强大的数据库支持、与 Windows 编程紧密结合以及成熟的组件技术。 |
| Visual Basse.NET | y用 .NET 语言开发的程序源代码被编译为中间代码 MSIL 然后通过 .NET Framework 的通用语言运行时(CLR)来执行。 |
程序设计语言分类
根据设计程序的方法将程序语言大致分为命令式和结构化程序设计语言、面向对象的程序设计语言、函数式程序设计语言和逻辑型程序程序设计语言等。
1、命令式和结构化程序设计语言
通常所以称的结构化程序语言属于命令式语言类,其结构特性主要反映在以下几个方面:
- 用自顶向下逐步精化的方法编程
- 按模块组织的方法编程
- 程序只包含顺序、判定(分支)及循环构造
C、PASCAL 等都是典型的结构化程序设计语言。
2、面向对象的程序设计语言
C++、Java 和 Smalltalk 是面向对象程序设计语言的代表,它们都必须支持新的程序设计技术,如数据隐式、数据抽象、用户定义类型、继承和多态
3、函数式程序设计语言
优点是对表达式中出现的任何函数都可以用其他函数来代替,只要这些函数调用产生相同的值。
函数式语言的代表 LISP 在许多方面与其他语言不同,最为显著的是,其程序和数据的形式是等价的,这样的数据结构就可以作为程序执行,程序也可以作为数据修改。常见的函数式语言有 Hashell、Scala、Scheme、APL 等。
4、逻辑型程序设计语言
是一类以形式逻辑为基础的语言。
程序设计语言的基本成分
程序设计语言的数据成分
1)常量和变量
按照程序运行时数据的值能否改变,将数据分为常量和变量。程序中的数据对象可以具有左值和(或)右值,左值指存储单元(或地址、容量)。变量具有左值和右值,在程序运行过程中其右值可以改变;常量只有右值,在程序运行过程中其右值不能改变。
2)全局量和局部量
数据按在程序代码中的作用范围(作用域)可以分为全局量和局部量。一般情况下,全局变量的作用域为整个文件或程序,系统为全局变量分配的存储空间在程序运行的过程中是不改变的,局部变量的作用域为定义它的函数或语句块,为局部变量分配的存储单元是动态改变的。
3)数据类型
按照数据组织形式的不同可将数据分为基本类型、用户定义类型、构造类型及其他类型。C(C++)的数据类型如下:
- 基本数据类型:整型(int)、字符型(char)、实型(float、double)和布尔类型(bool)
- 特殊类型:空类型(void)
- 用户定义类型:枚举类型(enum)
- 构造类型:数组、结构、联合
- 指针类型:type*
- 抽象数据类型:类类型
程序设计语言的运算成分
程序设计语言的控制部分
顺序结构

选择结构
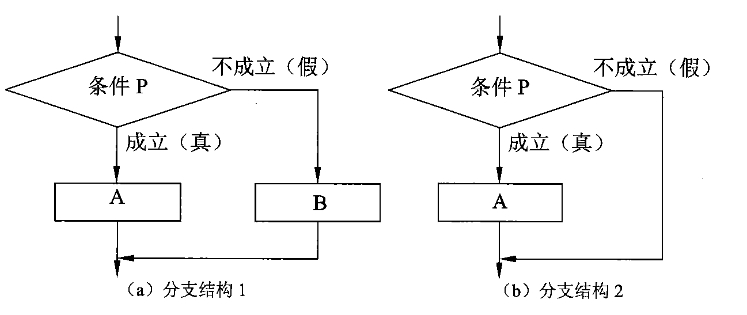
选择结构提供了在两种或多种分支中选择其中一个的逻辑。基本的选择结构是指定一个条件P,然后根据条件的成立与否决定控制流计算A和B,从两个分支中选择一个执行(如图a)。选择结构中的计算A或B还包含顺序、选择和重复结构。程序设计语言中还通常提供简化了的选择结构,也就没有计算 B 的分支结构,(如图b)。
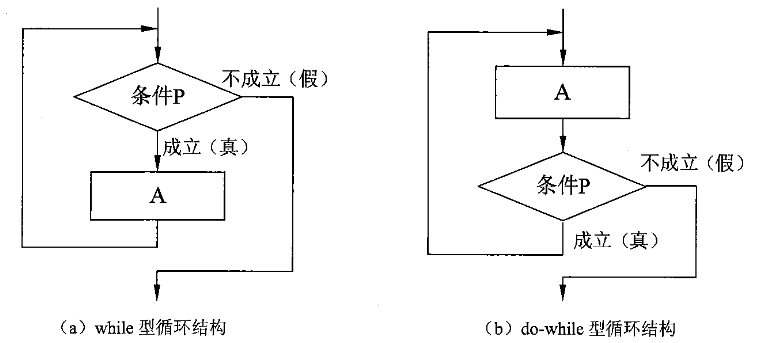
循环结构
主要有两种形式:while 型 和 do-while 型循环结构。
C(C++)语言提供的控制语句
- 复合语句。是一系列用”{“和”}”括起来的声明和语句,主要作用是将多条语句组成一个可执行单元。复合语句是一个整体,要么全部执行,要么一句也不执行。
- if 语句和swith语句
- 循环语句
程序设计语言的传输成分
指明语言允许的数据传输方式,如赋值处理、数据的输入和输出等。
函数
函数是程序块的主要成分,它是一段具有独立功能的程序。
语言处理程序基础
语言处理程序是一类系统软件的总称,主要作用是将高级语言或汇编语言编写的程序翻译成某种机器语言程序,使程序可在计算机上运行。语言处理程序主要分为汇编程序、编译程序和解释程序3中基本类型。
汇编程序基本原理
汇编语言
是为特定的计算机设计的面向机器的符号化的程序设计语言。
汇编语言源程序由若干语句组成,其中可以有三类语句:指令语句、伪指令语句和宏指令语句。
指令语句
又称机器指令语句,其汇编后能产生相应的机器代码,这些代码能被 CPU 直接识别并执行相应的操作。基本的指令有 ADD、SUB 和 AND 等,书写指令语句时必须遵循指令的格式要求。
指令语句可分为传送指令、算术运算指令、逻辑运算指令、移位指令、转移指令和处理机控制指令等类型。
伪指令语句
指汇编程序在汇编源代码时完成某些工作,例如为变量分配存储单元地址,给某个符号赋一个值等。
伪指令语句和指令语句的区别是:伪指令语句经汇编后不产生机器代码,而指令语句经汇编后要产生相应的机器代码。伪指令语句所指示的操作是在源程序被编译时完成的,而指令语句的操作必须在程序运行时完成。
宏指令语句
在汇编语言中,还允许用户将多次重复使用的程序段定义为宏。每个宏都有相应的宏名。在程序的任意位置,若需要使用这段程序,只要使用该宏名就使用了这段程序。因此,宏指令语句就是宏的引用。
汇编程序
功能是将用汇编语言编写的源程序翻译成机器指令程序。
汇编程序一般需要两次扫描源程序才能完成翻译过程。
第一次扫描的主要工作是:定义符号的值并创建一个符号表ST,记录汇编时所遇到的符号的值。还有一个固定的表MOT1,记录每条机器指令的记忆码和指令的长度。为了计算各汇编语句标号的地址,需要设立一个位置计数器或单元地址计数器LC,初始值一般为0。
汇编程序第一次扫描的过程:
单元计数器初始值为0
打开源程序文件
从源程序中读入第一条语句
while(若当前语句不是END语句){
if(语句有标号)将标号和单元计数器LC的当前值填入符号表ST;
if(语句有可执行的汇编指令语句)查找 MOT1 表获取当前指令的长度K,并令 LC=LC+K;
if(指令是伪指令)查找 POT1 表并调用相应的子程序;
if(指令的操作码是非法记忆码)调用出错处理子程序。
从源程序中读取下一条语句;
}
关闭源程序文件
汇编程序第二次扫描的任务是产生目标程序。
编译程序基本原理
编译过程概述
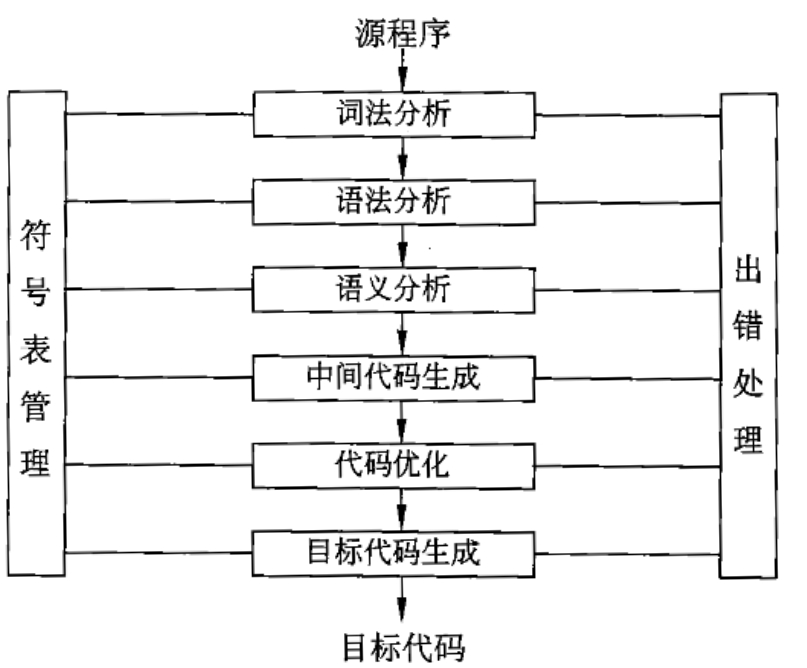
1)词法分析
对源程序从前到后(从左到右)逐字符的扫描,从中识别出一个个”单词”符号。(单词:关键字、标识符、常数、运算符和分割符)
2)语法分析
确定整个输入串是否构成一个语法上的正确程序
3)语义分析
分析各词法结构的含义。
4)中间代码生成
根据语义分析的输出生成中间代码。
5)代码优化
因为中间代码的生成是机械的、按固定模式进行的,所以在时间和空间上有较大的浪费。要生成高效的代码就得进行优化。优化一般建立在对程序的控制流和数据流分析的基础之上,与具体的机器无关。可在中间代码生成或目标代码生成阶段进行。
6)目标代码生成
把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码。此阶段与机器密切相关。
7)符号表管理
符号表的作用是记录源程序中各个符号的必要信息。符号表的建立可以在词法分析、语法分析、语义分析阶段
8)出错处理
在逻辑上分为前端和后端。前端(包括从词法分析到中间代码生成),后端(中间代码优化和目标代码优化)
以中间代码为分水岭,把编译器分为与机器有关的部分和与机器无关的部分。
文法和语言的形式描述
1)字母表、字符串、字符串集合与运算

2)文法和语言的形式描述
定义:描述语言语法结构的规则
分类:0型、1型、2型、3型(差别在于对产生式要施加不同的限制);0型又称短语文法,递归可枚举的、1型又称上下文有关文法、2型又称上下文无关文法、3型文法等价正规式
3)句子和语言
- 推导与直接推导
- 直接规约和规约
- 句型和句子
- 语言
4)文法的等价
文法 G1 和 G2 产生的语言相同
语法分析
词法规则可用3型文法(正规文法)或正规表达式描述,它产生的集合是语言基本字符集 $\Sigma$ (字符表)上的字符串的一个子集,称为正规集。
1)正规表达式和正规集
- $\varepsilon$是一个正规式,它表示集合 $L\left( \varepsilon \right) =${$\varepsilon$}
- 若 $a$ 是 $\Sigma$ 上的字符,则 $a$ 是一个正规式,它所表示的正规集合为 {$a$ }
- 若正规表达式 r 和 s 分别表示 $L\left( r\right)$ 和 $L\left( s\right)$,则
- r|s 式正规式,表示集合 $L\left( r\right)$ U $L\left( s\right)$
- r*s 是正规式,表示集合$L\left( r\right)$ $L\left( s\right)$
- $r^{\ast }$是正规式,表示集合$\left( L\left( r\right) \right) ^{\ast }$
- $\left( r\right)$是正规式,表示集合$L\left( r\right)$
仅通过有限地使用上述3个步骤定义的表达式才是$\Sigma$ 上的正规式,其中,运算符“|” “.” 和 “” 分别称为 “或”“连接”和“闭包”。在正规式的书写中,连接运算符 “.” 可以省略。运算优先级(高到低)为 . |
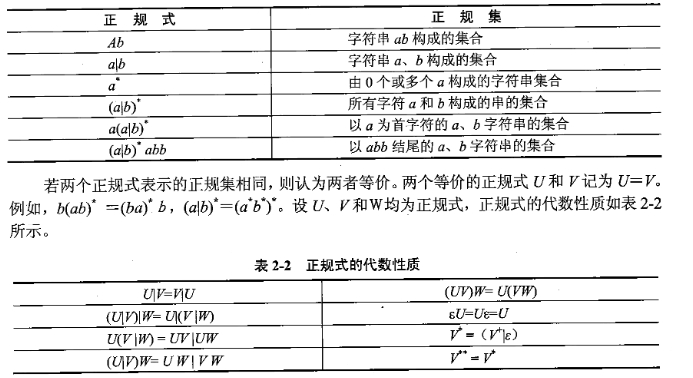
设 $\Sigma$ ={a,b} ,列出 $\Sigma$ 上的一些正规式和相应的正规集:
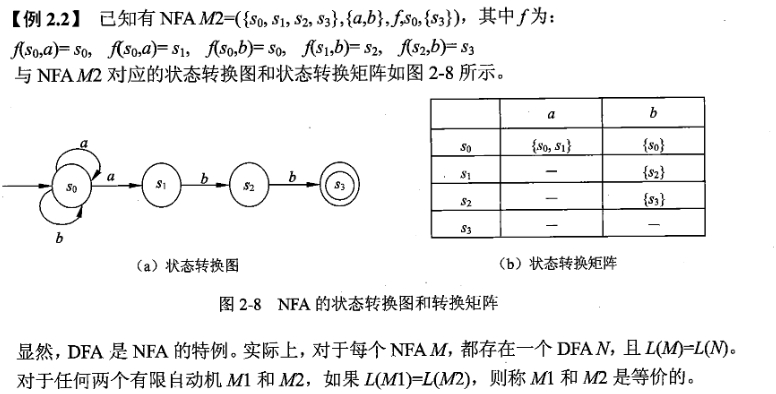
2)有限自动机
是一种识别装置的抽象概念,它能准确的识别正规集。分为确定的有限自动机(DFA)和不确定的有限自动机(NFA)。
确定的有限自动机(DFA)。由五个元组(S, $\Sigma$,$f$,$S_{0}$,Z)其中:
- S 是一个有限集,其每个元素称为一个状态
- $\Sigma$是一个有穷字母表,其每个元素称为一个输入符
- $f$ 是 $S\times \Sigma \rightarrow 2^{s}$ 上的单值部分映像。$f\left( A,a\right) =Q$表示当前状态为A、输入为 $a$ 时,将转换到下一个状态 Q,称Q为A的一个后继状态
- $S_{0}\in S$,是唯一的一个开始状态
- Z 是非空的终止状态集合,$Z\subseteq S$
注意:DFA 中的每个状态对应转换图中的一个结点,每个转换函数对应一条有向弧,若转换函数为$f\left( A,a\right) =Q$,则该有向弧从结点A出发,进入到Q,字符 $a$ 是弧上的标记

不确定的有限自动机(NFA)。也是由五个元组,它与确定有限自动机的区别如下:
- $f$ 是 $S\times \Sigma \rightarrow 2^{s}$ 上的映像。对于 S 中的一个给定状态及输入符合,返回一个状态的集合。即当前状态的后继状态不一定是唯一的。
- 有向弧上的标记可以是 $\varepsilon$
3)NFA 到 DFA 的转换
定义转换过程中需要的计算:
1、若 $I$ 是 NFA M 的状态集合的一个子集。定义$\varepsilon$_CLOSURE($I$) 如下:
- 状态集$I$ 的 $\varepsilon$_CLOSURE($I$) 是一个状态集
- 状态集 $I$的所有状态属于 $\varepsilon$_CLOSURE($I$)
- 若 $S\in I$,那么从 S 出发经过任意条 $\varepsilon$ 弧达到的状态 S’ 都属于 $\varepsilon$_CLOSURE($I$)
状态集合 $\varepsilon$CLOSURE($I$) 称为 $I$的 $\varepsilon$闭包。
由上可知,$I$ 的 $\varepsilon$_闭包 就是从状态集$I$ 的状态出发,经 $\varepsilon$ 所能到达的全体。假定 $I$ 是 NFA M 的状态集的一个子集,$a$ 是 $\Sigma $ 中的一个字符,定义:
$I_{a}$ = $\varepsilon$_CLOSURE(J)
J 是那些可以从 $I$中的某一状态结点出发经过一条 $a$弧而到达的状态结点的全体。
2、NFA 转换为 DNF 。
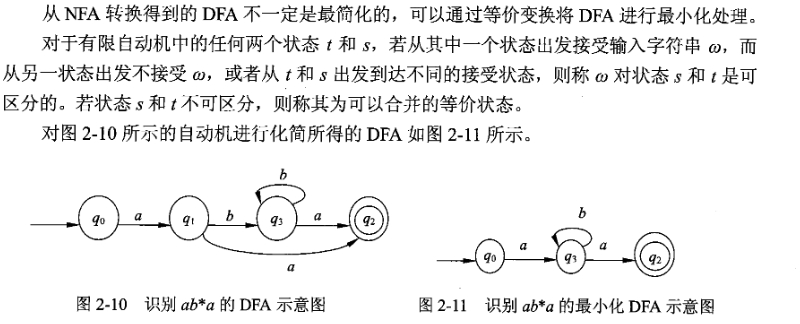
4)DFA 的最小化
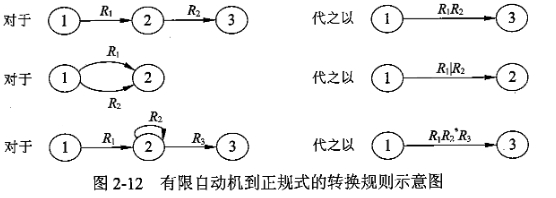
正规式与有限自动机的转换
1)有限自动机转换为正规式
2)正规式转换为有限自动机
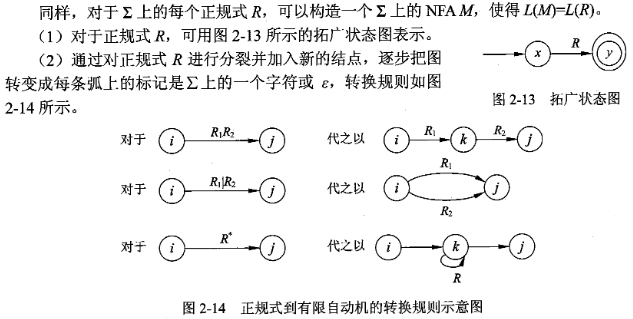
词法分析器的构造
步骤:
(1)用正规式描述语言中的单词构成规则
(2)为每个正规式构造一个 NFA ,它识别正规式所表示的正规集
(3)将构造出的 NFA 转换称等价的 DFA
(4)对 DFA 进行最小化处理,使其最简
(5)从 DFA 构造词法分析器
语义分析
任务是分析单词串是否构成表达式、语句和程序等基本语言结构,同时检查和处理程序中的语法错误。
程序语言的绝大多数语法规则采用上下无关文法进行扫描。
根据产生的语法树的方向,可分为自底向上和自顶向下两类。
1)上下文无关文法
规范推导;短语、直接短语和句柄;
2)自顶向下语法分析方法
基本思想:对于给定的输入串 $\omega$ ,从文法的开始符号 S 出发进行最左推导,直到得到一个合法的句子或者发现一个非法结构。在推导的过程中试图用一切可能的方法,自上而下、从左到右地输入串 $\omega$ 建立语法树。整个过程是一个反复试探的过程。
- 消除文法的左递归
- 提起公共左因子
- LL(1) 文法
- 递归下降分析法
- 预测分析法
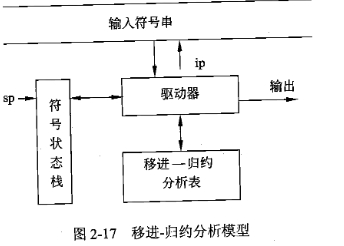
3)自底向上语法分析方法
又称移进-归约分析法。基本思想是:对输入序号 $\omega$ 自左向右进行扫描,并输入符号逐个移进栈中,边移进边分析,一旦栈顶符号串形成某个句型的归约串,就用某个产生式的左部非终结符来替代,这一步称为归约。重复这一过程,直到栈中只剩下文法的开始符号且输入串也被扫描完为止。